In this tutorial, we are going to learn and understand data preprocessing using pandas and numPy
Why is Data pre-processing important?
Data preprocessing is a crucial task in machine learning because often raw dataset contains inconsistency, noise, missing value, and redundant information. This kind of problem may impact on the performance of the model. Preprocessing ensures that the dataset is clean, structured, and suitable for modeling.
To understand the basics of pandas you can visit: Data Wrangling using Pandas
Step 1: Import required libraries
In this tutorial, we will focus on pandas and Numpy. So we will import these two libraries.
import pandas as pd import numpy as np
Step 2: Load the Dataset
data = {
'Age': [25,25, np.nan, 30, 35, 40, np.nan, 50 , np.nan],
'Salary': [50000,50000 ,54000, np.nan, 62000, 72000, 80000, np.nan,np.nan],
'City': ['Delhi','Delhi' ,'Mumbai', 'Pune', np.nan, 'Kolkatta', 'Benguluru', 'Hyderabad',np.nan]
}
df = pd.DataFrame(data)
print(df)
Output:

Step 3: Handing Missing Values
There are two methods to handle missing values.
- Removing Missing Values
- Imputing Missing Values
df.info()
Output:
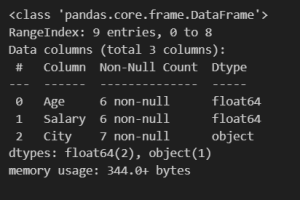
Let’s check if there are any missing values.
df.isnull().sum()
Output :
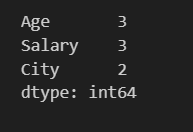
3.1 Removing Missing Values
This method is used when we have a large dataset and many fields of record are empty. We can see that there is a row having empty values. If we find such empty records we can easily drop them.
df.dropna(how='all', inplace=True) print(df)
Output :
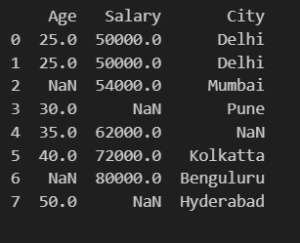
3.2 Imputing Missing Values
This method is used to handle missing values in numerical fields. We can impute them with statistical terms mean, median, and mode according to preference
Here we have two numerical columns ‘Age’ and ‘Salary’. Age is an integer value so if we have to impute that field we have to impute it with an integer. So If we take the median of nonempty records it will be an integer. For Salary, we can take the mean of nonempty records which can maintain the distribution of records.
df['Age'].fillna(df['Age'].median(), inplace=True)
df['Salary'].fillna(df['Salary'].mean(), inplace=True)
df['City'].fillna('Unknown', inplace=True)
print(df)
Output :
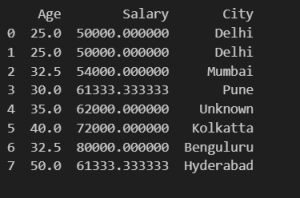
After handling missing values we can see there are duplicate data so we remove duplicates.
df.drop_duplicates(inplace=True) print(df)
Output :
Step 4: Data Transformation
Machine learning models require numerical inputs. So we convert categorical data into numerical format. There are the following types of encoding:
-
One Hot Encoding
-
Label Encoding
Here we are going to perform Label Encoding. We give labels to the city as per the following.
print(f"Label Encoding for {'City'}:")
print(dict(enumerate(df['City'].astype("category").cat.categories)))
Output :
Label Encoding for City:
{0: 'Benguluru', 1: 'Delhi', 2: 'Hyderabad', 3: 'Kolkatta', 4: 'Mumbai', 5: 'Pune', 6: 'Unknown'}
Now we replace these labels with cities in records.
df['City'] = df['City'].astype('category').cat.codes
print(df)
Output :

Conclusion
In this tutorial, we have learned the basics of preprocessing.
- Handled Missing Values
- Removed Duplicates
- Converted categorical data
Now the data is clean and ready for machine learning modeling.