Have you ever wondered whether you should use train/train split or go for cross validation when evaluating your machine learning model?
This decision can significantly impact your model’s performance and generalization to unseen data.
Let’s break it down in a simple and practical way, using examples from scikit-learn, so you can confidently choose the right method at the right time.
What are we building ?
We are going to learn the difference between train/test split and cross validation, their pros and cons, and when to use each. We will also build code examples that show how to implement both methods using Python and Scikit-learn.
By the end , you will know:
- Why train/test split might lead to misleading results if not used carefully
- How cross validation helps overcome that
- When one is better than the other
How does it work?
Both Train/Test Split and Cross-Validation are crucial techniques in machine learning for evaluating model performance and preventing overfitting. Scikit-learn provides excellent tools for implementing both. Choice of which to use depends on various factors, primarily the size of your dataset and the desired robustness of your model evaluation.
1.Train/Test Split
It is the simplest method of model evaluation. You divide your dataset into two distinct subsets:
- Training Set: Used to train your machine learning model. The model learns patterns and relationships from this data.
- Test Set: A completely unseen portion of the data used to evaluate the model’s performance after it has been trained. This provides an estimate of how well the model will generalize to new ,real world data.
When to use:
- Large Datasets: When you have a very large dataset, a single train/split might be sufficient to get a relaible estimate of performance because the test set is already large enough to be representative.
- Quick Initial Evaluation: For a rapid, preliminary assessment of a model’s performance, especially during the early stages of development.
- Computational Efficiency: It’s computationally less expensive than cross validation, as the model is trained only once.
- Final Model Evaluation: After you have performed hyperparameter tuning, you use a final , completely unseen test set to get an unbiased estimate of your chosen model’s performance.
Disadvantages:
- High Variance: The performance estimate can be highly dependent on the specific random split. Different splits might lead to different performance scores, especially with smaller datasets.
- Less Robust: It may not give a reliable estimate of model performance if the dataset is small or if the random split results in an unrepresentative test set.
- Data Usage: Not all data is used for training the final model(a portion is always held out for testing ).
Code:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_diabetes
from sklearn.metrics import mean_squared_error
data = load_diabetes()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print("MSE using Train/Test Split:", mean_squared_error(y_test, predictions))
Output:
![]()
In the above code we did not entered the data manually , instead we load a pre built sample dataset from scikit-learn, specifically:
load_diabetes() is a built in dataset provided by scikit learn for practicing regression. It automatically gives you:
- data.data: a matrix of input feature (shape:442 x 10)
- data.target: a vector of target values (a person’s disease progression score)
But if you wanted to use your own dataset, you would repalce this part:
from sklearn.datasets import load_diabetes data = load_diabetes() X = data.data y = data.target
with something like this:
import pandas as pd
df = pd.read_csv("your_dataset.csv")
X = df.drop('target_column_name', axis=1)
y = df['target_column_name']
2. Cross Validation (k-fold)
Instead of one split, k-fold cross validation splits the dataset into k parts (folds), trains on k-1 parts, and tests one the remaining one – repeating this for all folds. The results are then averaged.
When to use:
- Small to Medium Datasets: When your dataset is not large enough for a single train/test split to be truly representative. Cross validation maximizes the use of available data for both training and testing.
- Robust Performance Estimation: To get a more reliable and less biased estimate of your model’s generalization performance. It reduces the variance of the estimate compared to a single train/test split.
- Hyperparameter Tuning: This is where cross validation shines. Techniques like GridSearchCV and RandomizedSearchCV internally use cross validation to evaluate different hyperparameter combinations, ensuring that generalizes well across different subsets of the data.
- Model Selection: When comparing different machine learning algorithms or different versions of the same algorithm, cross validation provides fairer comparison.
- Detecting Overfitting/Underfitting: By observing the performance across different folds, you can gain insights into whether your model is consistently performing well or if there’s significant variance, which might indicate overfitting to specific data subsets.
Disadvantages:
- Computationally Expensive: The model is trained and evaluated multiple times, which can be time consuming , especially for complex models or large datasets.
- Complexity: Can be slightly more complex to implement and interpret than a simple train/test split.
Code:
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_diabetes
import numpy as np
data = load_diabetes()
X = data.data
y = data.target
model = LinearRegression()
scores = cross_val_score(model, X, y, cv=5, scoring='neg_mean_squared_error')
mse_scores = -scores
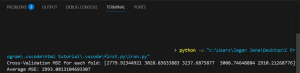
print("Cross-Validation MSE for each fold:", mse_scores)
print("Average MSE:", mse_scores.mean())
Output:
In summary:
- Train/test split: Good for quick checks on large datasets, and essential for the final , unbiased evaluation of your chosen model.
- Cross Validation: Provides a more robust and reliable estimate of model performance, especially important for smaller datasets and crucial for hyperparameter tuning and model selection.