This lecture will be about Text Clustering with Sklearn.
Basically, text clustering is a technique for unsupervised machine learning aimed at grouping a set of documents into various clusters. In this way, one can arrange a huge group of documents into meaningful document groups based on the actual content. This will be very important in the organization of documents, topic modeling, and activities aimed at discovering hidden trends in textual data.
Key Steps in Text Clustering:
Text Preprocessing: The raw text data needs to be put into a form appropriate for clustering. This includes removal of stop words, stemming, lemmatization, and eventually vectorizing the text.
Feature Extraction: Maintain a numerical representation of the text data. Commonly used techniques include TF-IDF(Term Frequency-Inverse Document Frequency) and word embeddings.
Clustering Algorithm: Run algorithms like K-means, DBSCAN, or Hierarchical Clustering.
Evaluation: The quality of the cluster is measured with metrics such as the Silhouette score or inertia, looking at it visually.
Example Code Using Sklearn
Here’s a step-by-step example of text clustering using Sklearn with the K-means algorithm and TF-IDF vectorization:
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# Sample data
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
"The quick brown fox jumps over the lazy dog.",
"Never jump over the lazy dog quickly.",
]
# Step 1: Text Preprocessing & Feature Extraction
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(documents)
# Step 2: Clustering
num_clusters = 2
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
kmeans.fit(X)
# Step 3: Analyze the clusters
clusters = kmeans.labels_
# Display the results
document_clusters = pd.DataFrame({'Document': documents, 'Cluster': clusters})
print(document_clusters)
# Optional: Visualize the clusters
pca = PCA(n_components=2)
scatter_plot_points = pca.fit_transform(X.toarray())
colors = ["r", "b", "g", "c", "m", "y", "k", "lime", "orange", "purple"]
plt.figure(figsize=(10, 7))
for i in range(num_clusters):
points = scatter_plot_points[clusters == i]
plt.scatter(points[:, 0], points[:, 1], s=50, c=colors[i], label=f'Cluster {i}')
plt.legend()
plt.title('K-means Clustering of Documents')
plt.show()
Explanation:
Sample Data: Lists of text documents to be clustered.
Text Preprocessing & Feature Extraction: A ‘TfidfVectorizer’ converts text documents into TF-IDF features used as input for clustering.
Clustering: K-means algorithm clusters documents into a specified number of clusters, num_clusters.
Analyzing the Clusters: Printing the obtained clusters tells which document belongs to which cluster.
Visualization: Reduction by PCA (Principal Component Analysis) of the TF-IDF features to 2 dimensions for the purpose of visualization.
The clusters are color-coded.
Output
Document Cluster 0 This is the first document. 1 1 This document is the second document. 1 2 And this is the third one. 0 3 Is this the first document? 1 4 The quick brown fox jumps over the lazy dog. 0 5 Never jump over the lazy dog quickly. 0
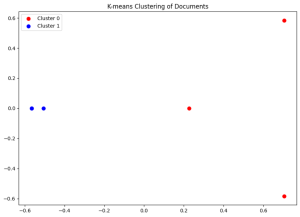
This example shows how to preprocess the text, then create features, apply a clustering algorithm, and plot it using Python with Sklearn.