Introduction
The “Get Company Website URL from Company Name” program is designed to help users quickly find the official website of a company by entering its name. The program automates the process of searching for the company’s website by querying a search engine (like Google), extracting the first result, and providing a direct link to the user.
This tool is especially useful when users need to find a company’s website without manually browsing through search results. By simply entering the company’s name, the program fetches the first result from the search engine, assuming it’s the correct official website. Users are then given the option to open the link in their browser directly, streamlining the search process.
However, direct scraping of search engines may be blocked, so the program should ideally use legal and more reliable means, such as Google’s Custom Search API, to obtain the URL. This ensures that users get accurate and up-to-date results in a compliant and efficient manner.
program
from bs4 import BeautifulSoup
import requests
import webbrowser
print("\tEnter Below To Get The Official URL")
name=input("Search Here:")
search=name
url='https://www.google.com/search'
headers = {
'Accept' : '/',
'Accept-Language': 'en-US,en;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',
}
parameters = {'q': search}
content = requests.get(url, headers = headers, params = parameters).text
soup = BeautifulSoup(content, 'html.parser')
search = soup.find(id = 'search')
first_link = search.find('a')
visit=first_link['href']
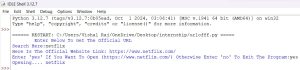
print("Here Is The Official Website Link:",visit)
op=input("Enter 'yes' If You Want To Open ("+visit+") Otherwise Enter 'no' To Exit The Program:").lower()
if op=='yes':
print("Opening....",name)
webbrowser.open(visit)
else:
print("Exiting The Program....")
Explanation
import necessary libraries
BeautifulSoup: This is a Python library for parsing HTML and XML documents. In this program, it’s used to extract the relevant parts of the search result’s HTML content.
requests: This library is used to send HTTP requests to websites. Here, it’s used to request the search result page from Google.
webbrowser: This module provides a high-level interface to allow displaying web-based documents in the default web browser. It will open the retrieved URL in the browser if the user chooses to do so.
user input for company name
print("\tEnter Below To Get The Official URL")
name = input("Search Here:")
search = name
print(): Displays a message to inform the user to enter a company name.
input(): Prompts the user to enter the name of the company they want to search for. This input is stored in the variable name, and it’s also assigned to search for later use when making the search request.
prepare URL for google search
url = 'https://www.google.com/search'
This sets the base URL for Google’s search page. The program will add the search query parameters to this URL to form a complete search request.
Set request headers
headers = {
'Accept': '/',
'Accept-Language': 'en-US,en;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',
}
These headers are passed along with the request to make it appear as if the request is coming from a real browser, rather than a script, which helps avoid being blocked by Google for automated scraping.
Accept: Specifies which media types the client can understand.
Accept-Language: This tells the server that the client prefers English .
User-Agent: This is critical, as it mimics a browser’s identity string, making the request look more like it’s coming from a user browsing with a real browser, avoiding detection as a bot.
Set search parameters
parameters = {'q': search}
Search Query (q): Google accepts the search query via the parameter q. This line assigns the user input (company name) to this parameter to form the search query. For example, if the user inputs “Tesla”, this will query Google for “Tesla”.
send HTTP GET request
response = requests.get(url, headers=headers, params=parameters)
requests.get(): Sends a GET request to the Google search page with the headers and query parameters. This sends the user’s search term along with the header information to Google.
response: The full HTML content of the search result is returned in the response object.
parse the HTML content
soup = BeautifulSoup(response.text, 'html.parser')
BeautifulSoup: The HTML content of the page (response.text) is passed to BeautifulSoup to be parsed. BeautifulSoup converts the HTML into a tree structure that allows for easy navigation and data extraction.
Extract the first search result
try:
search_results = soup.find(id='search')
first_link = search_results.find('a')
visit = first_link['href']
soup.find(): This line looks for the section in the HTML document with an ID of 'search', which typically contains all the search results.
search_results.find('a'): Inside the search section, it looks for the first anchor tag (<a>), which represents the first search result link.
first_link['href']: Extracts the URL (href attribute) from the first anchor tag. This is assumed to be the company’s official website.
Error Handling: A try block is used to prevent errors from crashing the program. If the expected elements aren’t found , the program will jump to the except block and print an error message.
print the found URL
print("Here Is The Official Website Link:", visit)
Once the first search result URL is found, it’s printed for the user to see.
Ask the user if they want to open the link
op = input("Enter 'yes' If You Want To Open (" + visit + ") Otherwise Enter 'no' To Exit The Program:").lower()
input(): Prompts the user to confirm whether they want to open the found URL. The user’s input is converted to lowercase using .lower() to make it easier to handle various input cases (e.g., “YES” or “yes”).
open the website or exit
if op == 'yes':
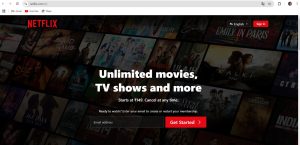
print("Opening....", name)
webbrowser.open(visit)
else:
print("Exiting The Program....")
f ‘yes’: If the user enters ‘yes’, the program opens the URL in the default web browser using webbrowser.open(visit).
If ‘no’: If the user enters ‘no’, the program prints a message and exits without opening the URL.
Handle errors
except AttributeError:
print("Sorry, no results were found or Google blocked the request.")
except AttributeError: If something goes wrong during parsing (like if no search results are found or if Google blocks the request), this block will catch the error and print a message indicating that no results were found. This prevents the program from crashing unexpectedly.
output
conclusion
In conclusion, the program that retrieves a company’s website URL from its name simplifies the process of locating official websites without manually sifting through search engine results. By automating the search and extraction process, the tool enhances user convenience, especially for those needing quick access to company information.
However, it’s important to recognize that scraping search engines directly, like Google, can lead to potential issues such as blocks or legal consequences, as it’s against their terms of service. A better and more sustainable approach would be to use APIs like Google Custom Search or Bing Search API to obtain reliable results while complying with the respective platform’s guidelines.
Despite its simplicity and usefulness, the program also faces challenges such as handling cases where no results are found, ensuring accuracy in the URL extracted, and maintaining compatibility with search engines’ evolving anti-scraping measures. Improving the tool by integrating API usage, robust error handling, and better result filtering will make it more reliable and efficient in helping users find the correct company website quickly.