Imbalanced datasets are a common challenge in machine learning. This occurs when one class has significantly fewer samples compared to the other, leading to biased models that favor the majority class. Such imbalances can result in misleading accuracy scores, as the model may predict the majority class correctly while failing to identify the minority class instances.
Handling imbalanced datasets can be quite tricky, but thankfully there are some handy techniques like SMOTE, ADASYN, and class weighing that can help make the task a lot easier. SMOTE (Synthetic Minority Over-sampling Technique) works by generating synthetic samples of the minority class to balance out the dataset. ADASYN (Adaptive Synthetic Sampling) takes it a step further by putting more focus on difficult-to-learn examples and generating even more synthetic samples for those instances. On the other hand, class weighing assigns higher weights to minority class samples during model training so that they have a greater impact on the learning process. By using these techniques, you can improve the performance of your models on imbalanced datasets and get more accurate predictions without having to worry about skewed results. Let us discuss these techniques with code examples.
SMOTE (Synthetic Minority Over-sampling Technique)
SMOTE is an oversampling technique that generates synthetic examples for the minority class rather than simply duplicating existing data. It does this by creating new samples along the lines connecting the existing minority class samples to their nearest neighbors. This ensures that the newly created samples introduce slight variations, making the dataset more diverse and helping the model learn better.
The way SMOTE works is straightforward. First, it selects a random sample from the minority class. Then, it finds its k-nearest neighbors and randomly selects one of them. A new synthetic sample is then generated along the line connecting the original sample and its selected neighbor. This process is repeated until the minority class reaches a desired size.
Basically, SMOTE works its magic by generating synthetic samples from the minority class to balance things out and give your model more diverse training data. By doing so, it helps prevent bias towards the majority class and improves overall performance. It’s like having a mini army of artificially created data points to give your algorithm a hand in making accurate predictions.
from imblearn.over_sampling import SMOTE
from collections import Counter
from sklearn.datasets import make_classification
# Create an imbalanced dataset with two classes
X, y = make_classification(n_classes=2, weights=[0.9, 0.1], n_samples=1000, random_state=42)
print("Before SMOTE:", Counter(y))
# Apply SMOTE for oversampling the minority class
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
print("After SMOTE:", Counter(y_resampled))
In this code :
- The make_classification function generates a dataset with two classes where 90% of samples belong to class 0 and only 10% to class 1.
- We use Counter(y) to print the number of instances in each class before applying SMOTE.
- SMOTE(random_state=42).fit_resample(X, y) balances the dataset by generating synthetic minority class samples.
- Finally, Counter(y_resampled) confirms that both classes now have an equal number of samples.
Ouput
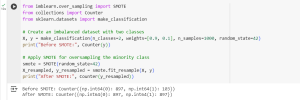
The dataset is now balanced, ensuring that the model receives equal exposure to both classes.
ADASYN (Adaptive Synthetic Sampling)
ADASYN is another oversampling technique similar to SMOTE, but with an adaptive approach. Instead of generating synthetic samples uniformly, ADASYN focuses more on the minority class samples that are harder to classify. This means that samples located near the decision boundary receive more synthetic samples, making the dataset more informative and improving the classifier’s ability to distinguish between classes.
Basically, what ADASYN does is it generates synthetic samples for the minority class in your dataset to balance things out and make sure your model doesn’t get biased towards the majority class. This way, your model can learn more effectively and accurately without getting confused by the imbalance in data. It’s like having a personal assistant that helps you stay on track and make better decisions.
By utilizing ADASYN in your machine learning projects, you can ensure that your models are trained on a more representative and balanced dataset, leading to more accurate predictions and better decision-making. This innovative technique not only helps prevent bias towards the majority class, but it also enhances the overall performance of your models by providing them with more diverse and relevant data. So, the next time you encounter imbalanced data, consider incorporating ADASYN into your workflow to optimize your machine learning outcomes and achieve more reliable results.
from imblearn.over_sampling import ADASYN
from collections import Counter
# Apply ADASYN for adaptive oversampling
adasyn = ADASYN(random_state=42)
X_resampled, y_resampled = adasyn.fit_resample(X, y)
# Print the exact class distribution
print("Before ADASYN:", Counter(y))
print("After ADASYN:", Counter(y_resampled))
In this code:
- We apply ADASYN(random_state=42).fit_resample(X, y) to generate synthetic samples based on the minority class distribution.
- Unlike SMOTE, ADASYN generates more samples for the harder-to-classify instances.
- Counter(y_resampled) confirms the final class distribution after applying ADASYN.
Output
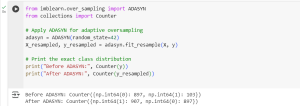
ADASYN does not necessarily create an exactly equal distribution but ensures that the additional samples help improve class separability.
Class Weighing
Another approach to handle imbalanced datasets is class weighing. Instead of modifying the dataset by oversampling the minority class, this technique assigns a higher weight to the minority class during model training. This means that the model will give more importance to the minority class instances when computing the loss function, ensuring that they influence the training process more significantly.
Basically, it’s a technique where you adjust the importance of different classes to make sure the model doesn’t just focus on the majority class. By assigning higher weights to the minority classes, you can make sure they have a greater impact on the model’s decision-making process. This helps improve overall performance and prevents bias towards the majority class. It’s like giving everyone an equal say at the table, even if some voices are quieter than others. Class weighing is a handy tool for making sure your model learns from all types of data, not just the most common examples.
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.utils.class_weight import compute_class_weight
# Convert class labels to a NumPy array
target_classes = np.unique(y)
# Compute class weights dynamically
class_weights = compute_class_weight(class_weight="balanced", classes=target_classes, y=y)
weights = dict(zip(target_classes, class_weights))
# Train logistic regression model with class weights
model = LogisticRegression(class_weight=weights, random_state=42)
model.fit(X, y)
weights = {int(k): float(v) for k, v in weights.items()}
print("Class Weights:", weights)
In this code:
- compute_class_weight(“balanced”, classes=[0,1], y=y) calculates the weight for each class based on their frequency.
- We store these weights in a dictionary so they can be passed to the model.
- LogisticRegression(class_weight=weights, random_state=42).fit(X, y) trains the model while considering the class weights.
- This ensures that the minority class gets more attention during training, reducing bias in predictions.
Output
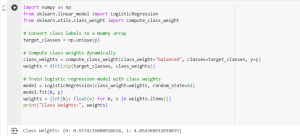
This means:
- Class 0 has a weight of 0.557, meaning it’s penalized less.
- Class 1 has a weight of 4.854, meaning misclassifications for this class are more heavily penalized.
Since class 1 has fewer samples, it gets a higher weight, ensuring the model pays more attention to it.
Conclusion
Handling imbalanced datasets is essential to ensure that machine learning models make accurate predictions across all classes rather than favoring the majority class. Three effective techniques to address class imbalance are:
- SMOTE, which generates synthetic samples for the minority class by interpolating between existing instances, effectively increasing diversity in the dataset.
- ADASYN, which further improves on SMOTE by focusing on harder-to-learn instances, ensuring that synthetic samples contribute to better decision boundaries.
- Class Weighing, which does not modify the dataset but instead assigns a higher importance to the minority class during model training, ensuring it receives adequate attention.
Each method has its advantages and should be chosen based on the dataset’s characteristics and the problem at hand. By applying these techniques, one can significantly improve the performance of machine learning models in handling imbalanced datasets, leading to more fair and accurate predictions.