Reading and Writing CSV file using Pandas
Reading CSV Files: To read a CSV file into a Pandas DataFrame, use the pd.read_csv() function:
# importing the pandas library
import pandas as pd
# Read csv file into a DataFrame
df = pd.read_csv("filepath.csv")
#Display the first five rows
print(df.head())
Writing CSV Files: After processing the data, you can write the DataFrame back to a CSV file using to_csv() function.
df.to_csv("output_filename.csv",index = False)
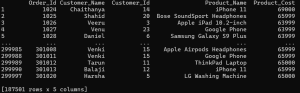
Sample DataSet:
The dataset (sales4.csv) contains following columns:
- Order_Id: unique identifier for each order.
- Customer_Name: Name of the customer who placced the order.
- Customer_Id: Unique identifier for each customer.
- Product_Name: Name of the product ordered.
- Product_Cost: Cost of the product ordered.
This dataset likely represents sales transactions, capturing details about individual orders and the associated customers and products.
import pandas as pd
df = pd.read_csv("sales4.csv")
print(df.head())
df.to_csv("sales4.csv", index = False)
output:

Filtering Data In Pandas:
.query():
The .query() method is used for filtering a DataFrame based on string expression. It’s similar to SQL-like syntax and provides a more readable and concise way to filter data.
Example: Filter rows where Product_cost is greater than 60000:
filtered = df.query('Product_Cost > 60000')
print(filtered)
output:
.iloc[]:
The iloc[] is used for indexed-based selection method.
We have to pass only integer index to select specific row/column.
By using this we can get rows or columns at particular positions in the index.
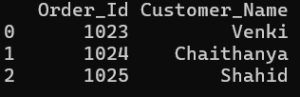
Example: select first 2 rows and the first 3 columns:
filtered1 = df.iloc[:3,:2] print(filtered1)
output:
.loc[]:
The .loc[] method is used for label-based indexing.
It filters rows and select specific columns.
Example: Filter rows where product_cost is greater than 60000 and select specific columns
filtered2 = df.loc[df['Product_Cost'] > 60000, ['Order_Id', 'Customer_Name', 'Product_Name']] print(filtered2)
output:
