Machine Learning Project: Anemia Detection
“Detect anemia we must, with the force of machine learning, progress we achieve.”- Not Yoda but close.
Introduction
Anemia is no laughing matter (although my puns might be). Affecting over 1.6 billion people globally, anemia is a condition where the body doesn’t produce enough red blood cells, leading to fatigue, weakness, and more severe health complications if untreated. With early detection, we can fight anemia effectively—and this is where a machine learning project can make a significant difference.
In this blog, I’ll take you on a journey through my Anemia Detection Using Machine Learning Project. Together, we’ll dive into data preprocessing, model training, and evaluation, and see how the power of Python and algorithms can be leveraged for good. And yes, there might be subtle nods to Yoda wisdom along the way. 🧑⚖️
The Dataset: The Foundation of This Machine Learning Project
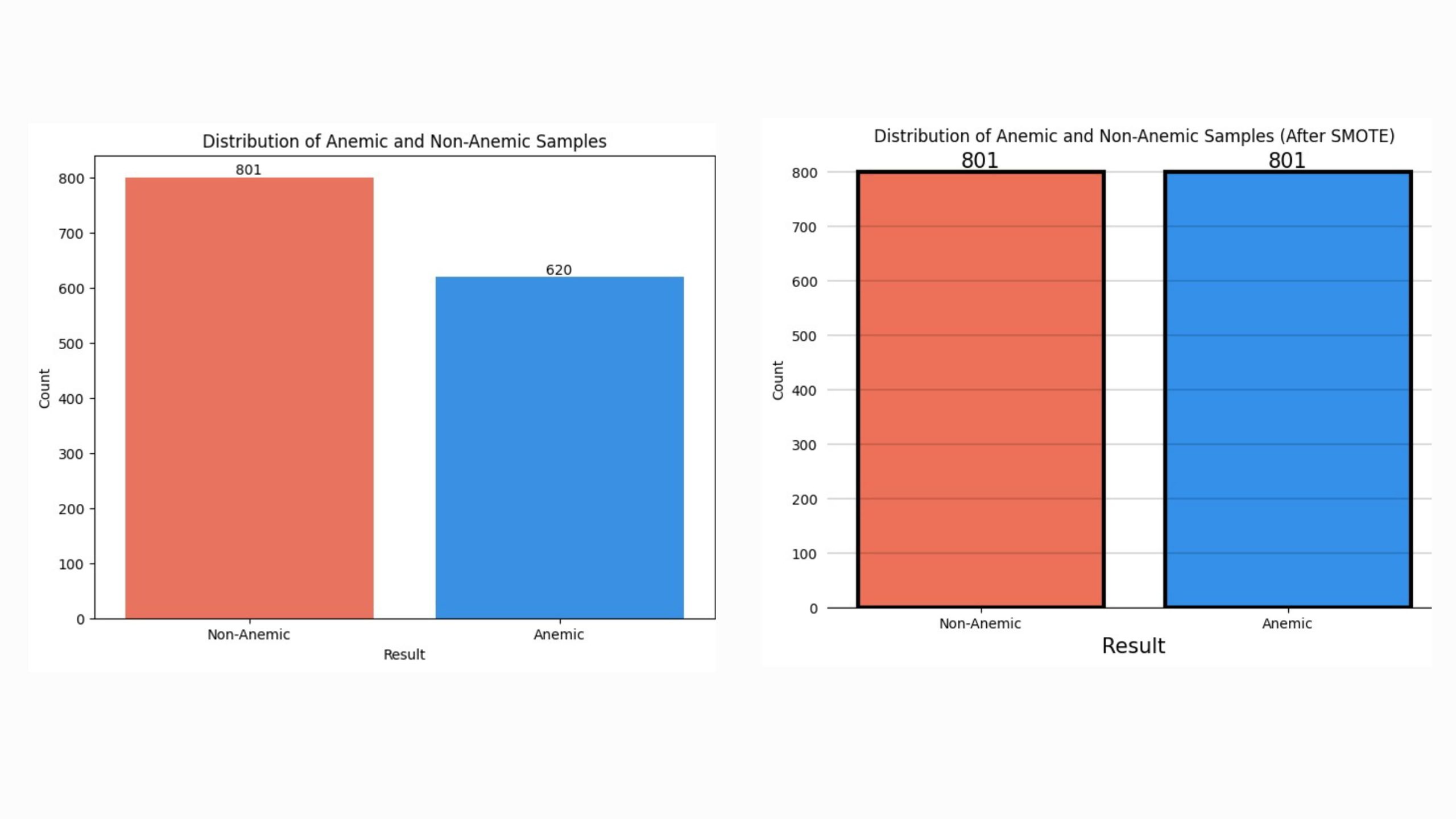
- For this project, I used a dataset containing features like hemoglobin levels, mean corpuscular volume (MCV), mean corpuscular hemoglobin (MCH), and other essential health markers.Here’s a quick glance at the dataset:
- Number of Features: 5 (including gender as a categorical feature)
- Target Variable: Binary (1 for anemic, 0 for non-anemic)
- Records: 801 rows of patient data (enough to train the force within the model). 🧬
Methodology: Steps in the Quest
1. Data Preprocessing 💻
This phase involved cleaning, feature engineering, and splitting the dataset into training and testing sets. Key steps included:
- Handling Missing Values: Removed rows with missing data (because incomplete data leads to incomplete models).
- Normalization: Scaled features to ensure no single variable dominates the training process.
- Encoding Gender: Converted categorical gender data into binary values for better algorithm compatibility.
“Balanced the dataset, SMOTE did. The dark side of imbalance, overcome it we did.” 🌟
2. Choosing the Right Algorithms 🧑💻
- To find the most effective model for anemia detection, I implemented and compared four algorithms:
- Random Forest 🌳: The wise Jedi of machine learning, combining multiple decision trees.
- SVM ⚔️: The one seeking the optimal hyperplane for separation.
- Logistic Regression 📊: Linear but reliable.
- KNN 🗺️: The friendly neighbor who checks with others before deciding.
3. Evaluation Metrics in This Machine Learning Project 🎯
A Jedi doesn’t rely on accuracy alone. Precision, recall, F1-score, and ROC-AUC were all evaluated. After all, correctly identifying an anemic patient (recall) is just as crucial as avoiding false alarms (precision).
Results: And the Winner Is…
Among the tested algorithms, Random Forest emerged victorious with the following metrics:
- Accuracy: 88% ✔️
- Precision: 85% 📏
- Recall: 87% 🔍
- F1-Score: 86% 🏅
KNN and Logistic Regression performed decently, but they lacked the robust predictive power Random Forest brought to the table. SVM, despite its reputation, struggled to handle the dataset’s complexity.
“To the top, Random Forest climbed. Accurate it is, balanced it remains.” 🔝
Tools of the Trade 🛠️
Every Jedi needs their lightsaber. For this project, mine included tools often used in machine learning projects for beginners and advanced learners alike…
- Python 🐍: The galaxy’s most versatile tool for machine learning.
- Scikit-learn: Where algorithms come alive.
- Flask: For deploying the model as an intuitive web app.
- Matplotlib & Seaborn: Visualizing the data to reveal hidden truths.
The Web Application: Bringing the Machine Learning Project to Life 🌐
After training the model, I developed a Flask-based web application to bring anemia detection to your browser, making this one of the most accessible machine learning projects with source code available for exploration. Users can input key health metrics (like hemoglobin and MCV), and the app predicts whether the patient is anemic.
With a clean interface and accurate predictions, this app is designed for healthcare professionals and researchers alike. It’s fast, reliable, and powered by the Random Forest model. 🚀
Check out the Deployed Web Application here 🖥️.
Future Directions 🔮
Like any good Jedi, I believe there’s always room for improvement. Here’s what the next version of this project could include:
- Larger Dataset: Incorporating more diverse data to improve model generalization.
- Feature Engineering: Exploring new health markers to enhance prediction accuracy.
- Real-time Monitoring: Integrating with wearable devices for continuous anemia risk assessment.
Conclusion 🚀
Through this project, I’ve demonstrated how machine learning can play a pivotal role in early anemia detection, saving time and potentially lives. The Random Forest model, combined with preprocessing techniques like SMOTE, proved to be the most effective in tackling this challenge.
“In health and technology, forward we must go. Predict anemia we must, and lives we may save.” 💡
Repository and Code 🔗
If you’re curious to explore the full project, including the dataset, code, and web application, check out my GitHub repository. Feedback and contributions are always welcome! 👨💻
Final Words from Yoda ✨
“Learn machine learning, one must. Apply for healthcare, save many lives, one can.” 🌟