Have you ever had two different datasets that you wanted to combine into one ? Just like putting together puzzle pieces, Pandas makes it incredibly easy to merge and join datasets.
In this guide, I will show you how to connect different DataFrames using Pandas functions.
What Are We Building?
We are going to build a small program that merges two different datasets like employee records and their department information into one single, organized table.
Think of it like this, you have one list with employee names and IDs, and another with department information based on those IDs. We will merge them so that each employee is linked to their department automatically.
How does It Work?
Pandas provides merge() and join() functions that work similarly to SQL joins .You can merge on one or more columns, and choose different join types :
- inner – only matching rows
- left – all rows from left DataFrame
- right – all rows from right
- outer – all rows from both, with missing filled as NaN
It’s like giving Pandas a set of rules for matching rows and watching it do the real hard work.
Now let us take 2 datasets , one with employees name and IDs, and another with department information based on those IDs. We will merge these datasets sing all these join types one by one .The data sets are as follows:

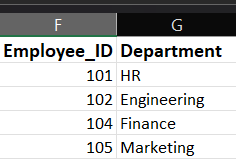
1. Inner Join
import pandas as pd
employees = pd.DataFrame({
'Employee_ID': [101,102,103,104],
'Name': ['Jagan', 'Raju', 'Vaibhav', 'Rahul']
})
departments = pd.DataFrame({
'Employee_ID': [101,102,104,105],
'Department': ['HR', 'Finance', 'Engineering', 'Marketing']
})
merged = pd.merge(employees, departments, on='Employee_ID', how='inner')
print(merged)
OUTPUT
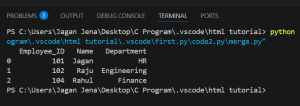
As we see, Vaibhav and and Marketing are excluded from the output.
This is because the inner join keeps only the matching rows (common Employee_IDs in both DataFrames).
Think of it as the intersection of both tables.
This case can be used when you only care about entries that exist in both datasets e.g., employees currently assigned to a department.
2. Left Join
import pandas as pd
employees = pd.DataFrame({
'Employee_ID': [101,102,103,104],
'Name': ['Jagan', 'Raju', 'Vaibhav', 'Rahul']
})
departments = pd.DataFrame({
'Employee_ID': [101,102,104,105],
'Department': ['HR', 'Finance', 'Engineering', 'Marketing']
})
merged = pd.merge(employees, departments, on='Employee_ID', how='left')
print(merged)
OUTPUT
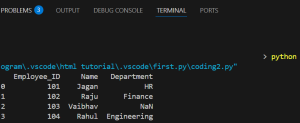
As we can see Vaibhav stays but since it has no department, it shows NaN.
This is because the left join keeps all rows from left table (employees), adds matching ones from departments and if no match is found then it fills it with NaN.
This case can be used when the main dataset is employees and you want to include all of them , even if they don’t belong to a department yet.
3. Right Join
import pandas as pd
employees = pd.DataFrame({
'Employee_ID': [101,102,103,104],
'Name': ['Jagan', 'Raju', 'Vaibhav', 'Rahul']
})
departments = pd.DataFrame({
'Employee_ID': [101,102,104,105],
'Department': ['HR', 'Finance', 'Engineering', 'Marketing']
})
merged = pd.merge(employees, departments, on='Employee_ID', how='right')
print(merged)
OUTPUT
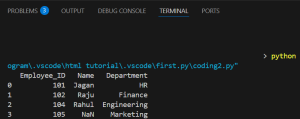
As we can see this time marketing is included but there is employee with ID 105, so Name is NaN.
This is because the Right Join keeps all rows from the right table (departments), adds matches from employees and if no match is found then fills it with NaN.
This case can be used when your primary focus is on departments and you want to see which positions are unfilled (e.g., Marketing has no one ).
4.Outer Join
import pandas as pd
employees = pd.DataFrame({
'Employee_ID': [101,102,103,104],
'Name': ['Jagan', 'Raju', 'Vaibhav', 'Rahul']
})
departments = pd.DataFrame({
'Employee_ID': [101,102,104,105],
'Department': ['HR', 'Finance', 'Engineering', 'Marketing']
})
merged = pd.merge(employees, departments, on='Employee_ID', how='outer')
print(merged)
OUTPUT
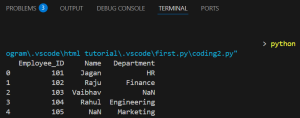
As we can see Vaibhav(103) from employees and Marketing (105) from departments are both shown and NaN is used for missing data.
This is because the outer join keeps all rows from tables and if a match is missing on either side, fills with NaN.
This can be used when you need a complete picture, even if some employees or departments are unmatched. Great for reporting mismatches or missing links.