Bagging and Boosting—a method of ensemble learning using Python
 Rohit Naresh Saktel
May 21, 2022
Rohit Naresh Saktel
May 21, 2022
In this tutorial, we will learn about the most widely used methods in data science in Python, which give power to machine learning models to improve their accuracy of prediction.
Before we go further with the methods, let us have a quick overview of ensemble learning.
Ensemble Learning: In ensemble learning, the training data is divided into a different number of *weak learners or classifiers. The predictive output of each model is then aggregated into the form of a group, producing a strong classifier with better model performance.
*A single model, often referred to as a base or weak learner, may not perform well to produce precise decisions due to high variance or bias. Therefore, the accuracy of prediction for weak learners is less as compared with strong learners.
Basically, it combines multiple machine learning models into a predictive model in order to:
-Decrease *variance using bagging, or
-decrease *bias using boosting, or
-improve prediction using stacking.
This provides a composite prediction where the final accuracy is better than the accuracy of individual models.
*Bias- error rate occurs in training data.
*Variance- error rate occurs in testing data.
Ensemble learning depends on robustness and accuracy.
---> Robustness: ensemble models incorporate the predictions from all the base learners.
---> Accuracy: the ensemble model delivers accurate predictions and has improved performance.
Ensemble learning methods
Ensemble methods can be divided into two groups:
1) Sequential ensemble methods
2) Parallel ensemble methods
Sequential ensemble methods
- Base learners are generated consecutively.
- Basic motivation is to use the dependence between the base learner and
- The overall performance of a model can be boosted.
Parallel ensemble methods
- It is applied wherever the base learners are generated in parallel.
- The basic motivation is to use independence between the base learners.
**Model averaging is an approach to ensemble learning where each ensemble member contributes an equal amount to the final predictions.
**Weighted averaging is an extension of model averaging ensemble where the contribution of each member to the final predictions is weighted by the performance of a model. The model weights are small positive values and the sum of all weights equals 1, allowing the weights to indicate the percentage expected performance from each model.
The most widely discussed ensemble methods and used in practise are:
1) Bagging
2) Boosting
Bagging - Bagging, also known as bootstrap aggregation, is a parallel ensemble methods where the results of multple model are combined to get a generalized results from a single model. Bagging is responsible for reducing variance of an estimate / classifier by taking mean of multiple classifiers.
In bagging, a training dataset is divided into a number of samples, which is done by row sampling with replacement; a value can occur more than once for different samples. These samples are then used in training multiple models or base learners aggregated to form an ensemble. After the models are trained, a particular set of testing data is taken into consideration for predicting the results from each model. We are applying a *voting classifier to the outputs, which are then aggregated into a single model with better predictive performance and precise accuracy.
*voting classifier: a ML classifier that trains various base models to predict the most frequently occurring output for the different models.
Steps involved in bagging
- Bootstrapping: create randomly sampled datasets of the original training data.
- Parallel training - Build and fit several classifiers to each of these diverse copies.
- Aggregation - Take the average of all the prediction to make a final overall prediction.
One of the most widely used bagging techniques is the random forest classifier and regressor.Random Forest is a good example of a parallel ensemble learning method. Random forest mainly depends on the resampling of the training data, which is done by row sampling and feature/column sampling with replacement. Unlike bagging, different base learners are replaced by decision trees in random forest classifiers or regressors.
It is to be noted that if we change a particular sample of testing data set in a random forest, then it will not show any significant change in the accuracy of the single predictive model.
BAGGING DEMONSTRATION IN PYTHON
#import libraries
import pandas as pd
#load the dataset
dataset = pd.read_csv("parkinsons.csv")
dataset.sample(10)
#check missing values
dataset.isnull().sum()
# quick overview of a dataset
dataset.describe()
# counting the values in column--status
dataset.status.value_counts()
#initialize x and y variables
X=dataset.drop('status',axis='columns')
y=dataset.status
#dataset scalling
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled=scaler.fit_transform(X)
X_scaled[:3]
#splitting data into training and testing set
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split (X,y,stratify=y,random_state=10)
#shape of training set
X_train.shape
#shape of testing set
X_test.shape
# count values for training set
y_train.value_counts()
# define a decision tree classifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
results = cross_val_score(DecisionTreeClassifier(),X,y,cv=5)
results
#mean accuracy score
results.mean()
# Define a bagging classifier
from sklearn.ensemble import BaggingClassifier
model = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators = 100,
max_samples=0.8,oob_score=True,random_state=0)
model.fit(X_train, y_train)
#accuracy score--->training set
model.oob_score_
#accuracy score --> testing set
model.score(X_test,y_test)
# to use cross_val_score method
model = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators = 100,
max_samples=0.8,oob_score=True,random_state=0)
results = cross_val_score(model,X,y,cv=5)
results.mean()
# define a random forest classifier...
from sklearn.ensemble import RandomForestClassifier
results = cross_val_score(RandomForestClassifier(),X,y,cv=5)
results.mean()
OUTPUT

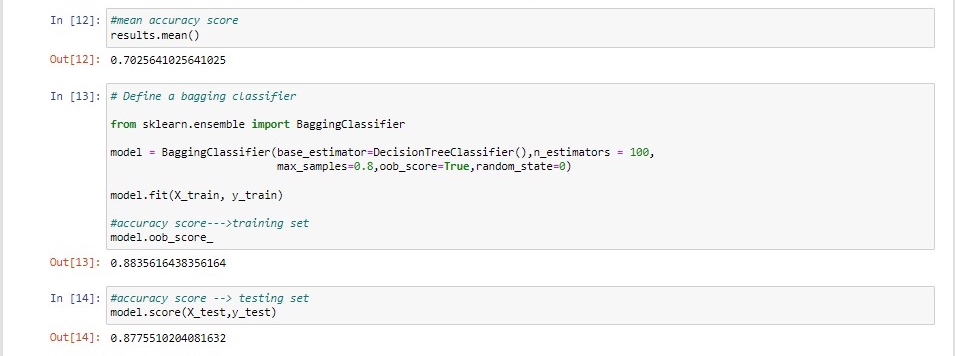

From the output image, you can observe that for a DT classifier, the accuracy score of testing data is somewhat higher than that of training data. This shows that our model is not an overfitting model.
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Boosting - Boosting is a sequential ensemble method where weak learners are trained sequentially to minimise training errors. In boosting, a random set of training data is used in training a particular weak learner and fitted with a model. If the error occurs after testing, then the error gets trained and fitted with another particular weak learner. And the process is done sequentially in order to reduce the bias of the single model.
Steps involved in boosting
- Train a classifier M1 that best classifies the data with respect to accuracy.
- Identify the regions where M1 produces errors, add weight to them, and produce an M2 classifier.
- Aggregate those samples for which M1 gives a different result from M2 and produces an M3 classifier. Repeat step 2 for a new classifier.
Algorithm used in Boosting :
- AdaBoost algorithm
- Gradient Boosting algorithm
- XgBoost algoritm
BOOSTING DEMONSTRATION IN PYTHON
#import libraries
import pandas as pd
#load the dataset
dataset = pd.read_csv("parkinsons.csv")
dataset.sample(10)
#check missing values
dataset.isnull().sum()
# quick overview of a dataset
dataset.describe()
# counting the values in column--status
dataset.status.value_counts()
#initialize x and y variables
X=dataset.drop('status',axis='columns')
y=dataset.status
#dataset scalling
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled=scaler.fit_transform(X)
X_scaled[:3]
#splitting data into training and testing set
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split (X,y,stratify=y,random_state=10)
#shape of training set
X_train.shape
#shape of training set
X_train.shape
# count values for training set
y_train.value_counts()
# define a decision tree classifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
results = cross_val_score(DecisionTreeClassifier(),X,y,cv=5)
results.mean()
#define a adaboost classifier...
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=10,random_state=0)
model.fit(X_train,y_train)
model.score(X_test,y_test)
OUTPUT



From the output image, you can observe that the accuracy score of the DT classifier denotes the model having more bias. Thus, applying boosting algorithm-AdaBoost leads to an improvement in the accuracy score by reducing the bias of the model.
Project Files
| .. | ||
| This directory is empty. | ||
