Check Sensitive Data in Document Using Python
 ABHISHEK KUMAR
May 25, 2023
ABHISHEK KUMAR
May 25, 2023
This project helps to prevent data loss or leaks by sharing documents. This program tells you what is the sensitive information in the paper.
CONTENTS:-
1. Project information
2. Project Requirement
3. Details
4. Source code
5. Output
Project Information:-
This is Data Loss Prevention Tools. Today many documents including text files and images are forwarded and circulating everywhere like on WhatsApp groups and other Social Media platforms, so for preventing Sensitive Information like credit card details and much essential information in documents. This tool detects sensitive information and tells you this is sensitive information and you can remove the sensitive information from the paper.
Project Requirement:-
>>Python 3 installed on the computer
>> Import mime types
>>import py-tesseract
>> From PIL import Image
Details:-
The program asks you to enter the type of document you want to be checked i.e. text file or image file then asks path of the document
and then checks sensitive information. And this program matches every text to the pattern (credit card number, email address, phone number);
If there is no image file then entered no. In the source code, you can also modify it by adding more patterns. This code has a limited number of patterns.
This code is very useful in checking documents and preventing sharing of sensitive information.
Source code:-
import re
import mimetypes
import pytesseract
from PIL import Image
# Define a list of sensitive data patterns
sensitive_patterns = [
r'\b\d{3}-\d{2}-\d{4}\b', # Social Security Number (SSN) pattern
r'\b(?:\d{4}-?){3}\d{4}\b', # Credit card number pattern
r'\b(?:\d{4}-?){2}\d{4}-?\d{4}\b', # Additional credit card number pattern
r'\b(?:\d{4}\s?){4}\b', # Another credit card number pattern
r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b', # Email address pattern
r'\b\d{10}\b' # Phone number pattern (10 digits)
]
# Function to scan text for sensitive data patterns
def scan_text(text):
matches = []
for pattern in sensitive_patterns:
matches.extend(re.findall(pattern, text))
return matches
# Function to analyze a file for sensitive data and file type
def analyze_file(file_path):
file_type = detect_file_type(file_path)
if file_type.startswith('image'):
text = extract_text_from_image(file_path)
if text is None:
print("Failed to extract text from the image.")
return
elif file_type.startswith('text'):
text = extract_text_from_text_file(file_path)
else:
print(f"Unsupported file type: {file_type}")
return
matches = scan_text(text)
if matches:
print(f"Sensitive data found in file: {file_path}")
print("Matches:", matches)
text = mask_sensitive_data(text, matches)
print("Masked Text:")
print(text)
else:
print(f"No sensitive data found in file: {file_path}")
print("File Type:", file_type)
# Function to detect the file type based on the file extension or content
def detect_file_type(file_path):
file_type, _ = mimetypes.guess_type(file_path)
if file_type is None or file_type == 'application/octet-stream':
file_type = guess_file_type(file_path)
return file_type if file_type else "Unknown"
# Function to guess the file type based on the file extension
def guess_file_type(file_path):
extension = file_path.split('.')[-1]
if extension.lower() in ('txt', 'text'):
return 'text/plain'
elif extension.lower() in ('jpg', 'jpeg', 'png', 'gif'):
return 'image/' + extension.lower()
return None
# Function to extract text from an image using OCR (Optical Character Recognition)
def extract_text_from_image(image_path):
try:
image = Image.open(image_path)
text = pytesseract.image_to_string(image)
return text
except IOError:
return None
# Function to extract text from a text file
def extract_text_from_text_file(file_path):
with open(file_path, 'r') as file:
text = file.read()
return text
# Function to mask sensitive data in the text
def mask_sensitive_data(text, matches):
for match in matches:
masked = "*" * len(match)
text = text.replace(match, masked)
return text
# Prompt the user to choose the file type and enter the file path
file_type = input("Enter the file type (text or image):")
if file_type.lower() == 'text':
file_path = input("Enter the text file path: ")
elif file_type.lower() == 'image':
file_path = input("Enter the image file path (type 'no' if not available): ")
if file_path.lower() == 'no':
file_path = None
else:
print("Invalid file type entered.")
exit()
if file_path is not None:
analyze_file(file_path)
else:
print("No file path provided. Exiting...")
Output:-
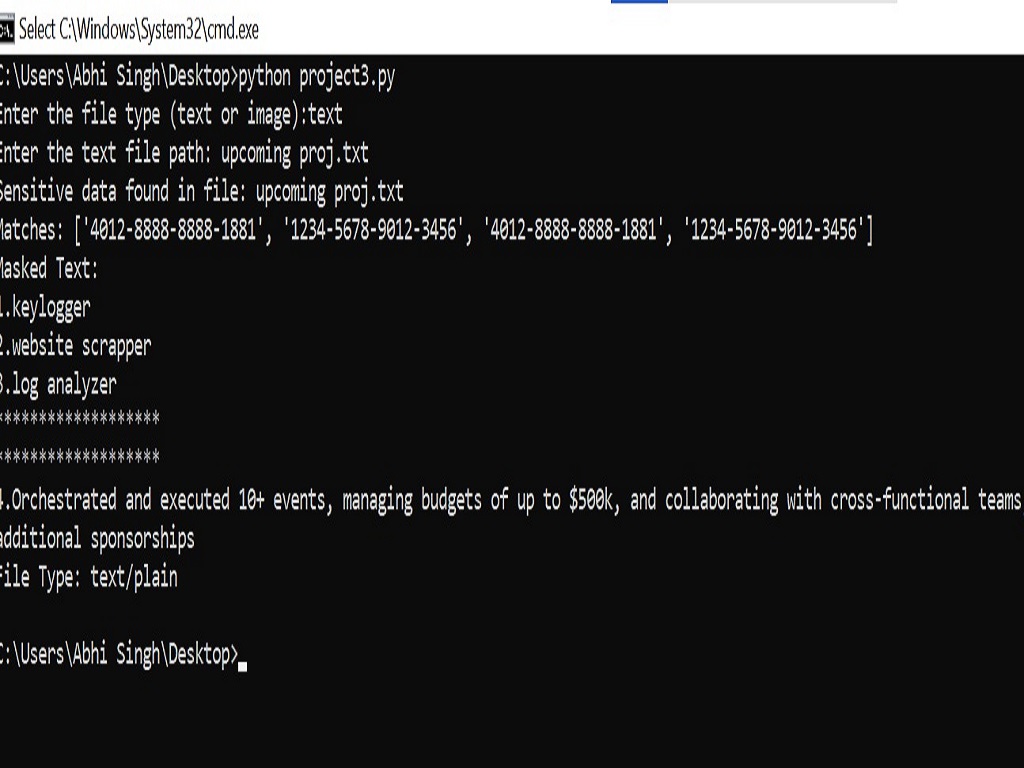
Project Files
| .. | ||
| This directory is empty. | ||
