Web Scraping GUI Application Using Python
 Jeet Chawla
Feb 14, 2021
Jeet Chawla
Feb 14, 2021
It is a desktop-based Web Scraper Application made using Python where you can provide the URL of the website you want to scrap and get the data accordingly.
Project Description :
The programming language used in this project was Python. Python is used worldwide on a large scale for web development, data science, and machine learning and it was highly ideal for this project as well. This project offers a GUI application capable of web scraping. Web Scraping is a great tool because it allows quick and efficient extraction of data from the desired source. Therefore, this application is really useful for the users. Exception handling was done wherever necessary.
User Constraints :
The user needs to have a good internet connection in order to use this application.
Hardware and Software Requirements
• MS-Windows Operating System
• Python IDLE (Python 3.6 or higher)
• Proper Internet connection
Major Libraries used :
PyQt5 - PyQt is a GUI widgets toolkit. It is a Python interface for Qt, one of the most powerful, and popular cross-platform GUI libraries. PyQt API is a set of modules containing a large number of classes and functions. Each widget in the GUI emits an action called a signal and the callable function linked to the signal is called a slot. The connect method is used to link a signal and a slot. We can create our methods to handle the signals or we can change the properties of already existing methods/functions for that particular widget. PyQt API contains more than 400 classes. Install this module using the command : pip install PyQt5 .
Urllib - It is a package that contains several modules for handling URLs. The urlopen method was used to fetch URLs using a variety of different protocols. The urllib.request module was used in this project for handling the URLs. This package can also be installed using the command: pip install urllib.
BeutifulSoup - It is a Python library for pulling out data from HTML and XML files. This is the backbone of the web scraper tool as it can search, navigate and modify the parse tree while working with the desired parser. The parser used in this project was lxml. This module can be imported from the bs4 package. The bs4 library can be installed using the command: pip install bs4 and the same way lxml parser can be installed.
Design and Functionality of GUI :
When the user runs the application, the main window appears. This main window was designed using the QWidget class object. This main widget includes a line edit field as a child widget, which was created using the QLineEdit class object. This field is used for inputting URLs from the user. There also exists a text browser for displaying the scraped data to the user. This child widget was created using the QTextBrowser class object. Also, there is a push button 'SCRAP URL' for scraping data and this was created using the QPushButton class object.
When the user runs the application, the main screen appears and the user can enter a valid URL for scraping. The user can now click on the 'SCRAP URL' button. In case, the URL is incorrect or there is poor internet connectivity, an exception is encountered which is handled by a display of a message to the user for the required rectification. If the URL is correct and the internet is also fine, the user can view the scraped data. This whole process can be understood as follows :
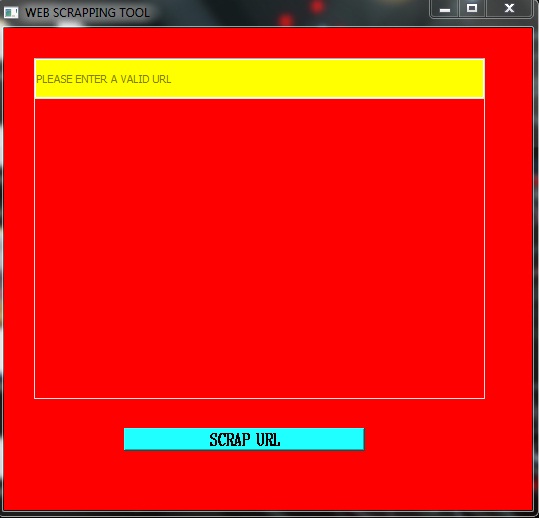
WEB SCRAPER MAIN SCREEN
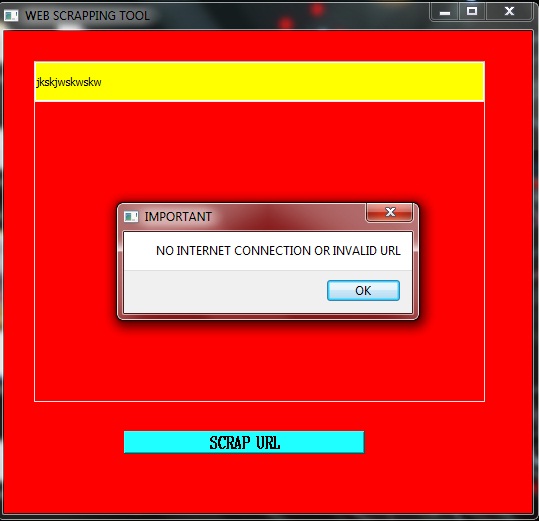
WEB SCRAPER ERROR MESSAGE

DATA SCRAPED SUCCESSFULLY
FOR RUNNING THE APPLICATION UNZIP THE PACKET AND FULFILL THE DESIRED SOFTWARE REQUIREMENTS. THEN AFTER INSTALLING ALL NECESSARY PYTHON PACKAGES, RUN THE webscrap.py file using PYTHON EDITOR.
Project Files
| .. | ||
| This directory is empty. | ||
