Grocery Items Recommendation using Apriori Algorithm in Python - Association Rule Learning
 ABISHEK KRISHNAPRASAD
Jul 26, 2020
ABISHEK KRISHNAPRASAD
Jul 26, 2020
This project focuses on recommending grocery items to a customer that is most frequently bought together, given a dateset of transactions by customers of a store.
Introduction:
Association rule mining is a technique to identify underlying relations between different items. Take an example of a Grocery store where customers can buy a variety of items. Usually, there is a pattern in what the customers buy. Say, fathers may buy beer along with diapers, these transactions involve a pattern. More profit can be generated if the relationship between the items purchased in different transactions can be identified, Association rule learning is a rule-based machine learning method for discovering relations between variables in large databases. The objective is to identify strong relations discovered in datasets using some measures such as support, confidence or lift.
For instance, if items X and Y are bought together then,
- X and Y can be placed together so that when a customer buys one of the products, he doesn't have to go elsewhere to buy the other product.
- People who buy one of the products can be targeted through an ad-campaign or collective discount offers to buy the other product.
- Both X and Y can be packed together.
The process of identifying an association between products is called association rule mining, it is an implicated expression of the form X→Y, where X and Y are separate item sets. A more concrete example based on consumer behavior would be {Diapers}→{Beer} suggesting that men who buy diapers are also likely to buy beer. To evaluate the interest of such an association rule, the support confidence and lift help to identify the statistical relations.
Support: The Support metric says how popular and repetitive an itemset is, i.e., The number of times an item occurs in a number of transactions, statistically it is the frequency of an itemset.
Support = Occurance of Item / Total number of transactions
Confidence: The Confidence metric says the strength of relation between two different itemsets, i.e., how likely an item Y is purchased, when an item X is purchased, expressed as {X -> Y}, This is measured by the proportion of transactions with item X, in which item Y also appears.
Confidence = Support (X Union Y) / Support(X)
Lift: It is the ratio of expected confidence to observed confidence; it is the measure of confidence of Y when item X was already known (X/Y) to the confidence of Y when X item is unknown. In other words, confidence of Y with respect to X and confidence of Y independent of X.
Lift = Support (X Union Y) / Support(X) * Support(Y)
Apriori Algorithm:
The Apriori algorithm works on the assumption of anti-monotonicity of the support metric, which means,
- All the subsets of a frequent itemset, must be frequent
- For any infrequent itemset, all its supersets must not be frequent
Step 1: Create a frequency table of all the items that occur in all the transactions.
Step 2: We know that only those elements for which the support is greater than the set threshold support is significant. i.e., (support of an individual item > threshold support)
Step 3: The next step is to construct all the possible pairs of the selected significant items irrespective of the order. i.e., XY is same as YX.
Step 4: The next step is to find the frequency of the occurrence of such similar and related pairs of items from all transactions, and only pairs of items that are greater than the specified threshold value of support is considered.
Step 5: With step 5, it is possible to construct any number of related items with the association metrics and rules.
Python Implementation:
The Dataset:
The dataset is a grocery store transaction list of food products and contains over 7500 transactions of customers, our objective is to find patterns relating the frequently bought items, the dataset can be found here.

Installing the Apyori Module:
It’s necessary to install the apriori module as it’s not an inbuilt module in Python.
#install the apriori module !pip install apyori
Importing the Libraries:
#import the necessary python libraries import pandas as pd import numpy as np from apyori import apriori
Importing the Dataset:
#importing the dataset, consider the header as it contains products
dataset = pd.read_csv('Market_Basket_Optimisation.csv', header = None)
dataset = dataset.fillna(0) #Fill 0 in place of nan values
Creating a list of transactions:
Apriori requires a list format for processing the items, so let’s create an empty list and append values in the following format,
#creating a list of transactions
transactions = []
for i in range(0, 7501):
transactions.append([str(dataset.values[i,j]) for j in range(0, 20) if str(dataset.values[i,j])!='0'])
Creating the Apriori Function and Setting the Parameter Threshold Values:
Now let’s create a variable ‘rules’ as an object of the apriori function and set the minimum threshold values for the metric parameters support, confidence and lift, a set of rules relating to the significant items greater than the threshold values will be selected, create another variable to view the items as a list.
#create an object of apriori function and set the threshold values for metrics rules = apriori(transactions, min_support=0.003, min_confidence=0.2, min_lift=3, min_length=2) rules_list = list(rules)
Converting the list as a DataFrame:
Convert the list of results to a dataframe for further operation and better visualization of the final results,
#converting the list to a dataframe result = pd.DataFrame(rules_list)
Visualizing the Results in a Proper Format:
For better visualization, we’ll create a separate column for the Support Metric and convert the orderstatistic in a proper format that includes the related items in two columns and the other association metrics: confidence and lift in the next two columns.
#save support to a separate column
support = result.support
#all four empty lists will contain the items, confidence and lift respectively.
item1 = []
item2 = []
confidence = []
lift = []
#first and second item are frozensets and it has to be converted to a list
for i in range(result.shape[0]):
list1 = result['ordered_statistics'][i][0]
item1.append(list(list1[0]))
item2.append(list(list1[1]))
confidence.append(list1[2])
lift.append(list1[3])
#convert the lists to dataframe
item_1 = pd.DataFrame(item1)
item_2 = pd.DataFrame(item2)
conf =pd.DataFrame(confidence,columns=['Confidence'])
lift_m = pd.DataFrame(lift,columns=['Lift'])
#concatenate the individual dataframes to a single dataframe
final_result = pd.concat([item_1,item_2,support,conf,lift_m], axis=1)
#fill the missing values
final_result = final_result.fillna(value=' ')
#rename the columns
final_result.columns = ['Item1','Item2','Item3','Item4','Item5','Support','Confidence','Lift']

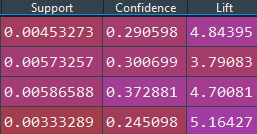
Conclusion:
Hence, the combination of items that are frequently bought together is displayed in the final results dataframe, along with the statistical metrics of each combination, this can be used for offers and recommendations, I hope you found the implementation helpful and gained an intuitive understanding of the Apriori Algorithm and it's efficacy on constructing associative rules.
Project Files
| .. | ||
| This directory is empty. | ||
