Heart Disease Prediction using Machine Learning - Python
 C Koushik
Feb 11, 2021
C Koushik
Feb 11, 2021
Classification models to predict 10-year risk of future coronary heart disease (CHD) using Python.
Objective:
The aim is to build a classification model that predicts heart disease in a subject. (note the target column to predict is 'TenYearCHD' where CHD = Coronary heart disease) using Python.
About the dataset:
The dataset is publicly available on the Kaggle website, and it is from an ongoing cardiovascular study on residents of the town of Framingham, Massachusetts. The classification goal is to predict whether the patient has a 10-year risk of future coronary heart disease (CHD). The dataset provides the patients’ information. It includes over 4,240 records and 15 attributes.
Components of this project:
1) Installing and importing necessary libraries
import numpy as np import pandas as pd import seaborn as sn import matplotlib.pyplot as plt from sklearn.utils import resample from sklearn.model_selection import train_test_split from sklearn.preprocessing import MinMaxScaler from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score from sklearn.model_selection import RandomizedSearchCV from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report
2) Data Cleaning
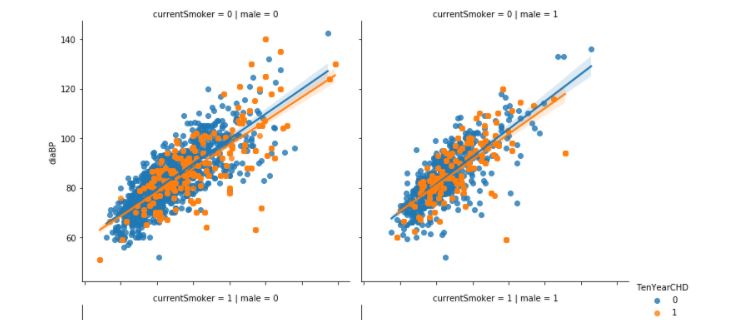
3) Exploratory Data Analysis
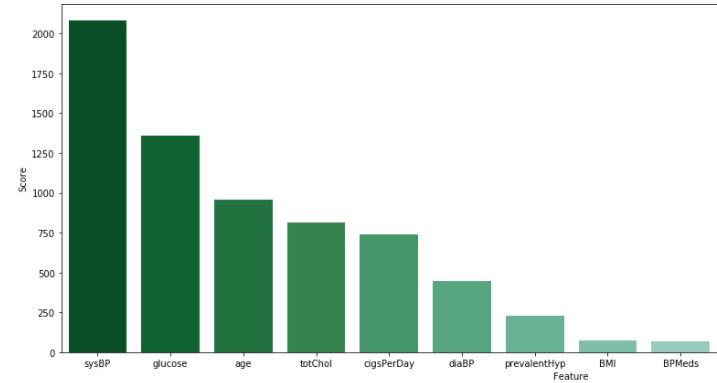
4) Feature Selection
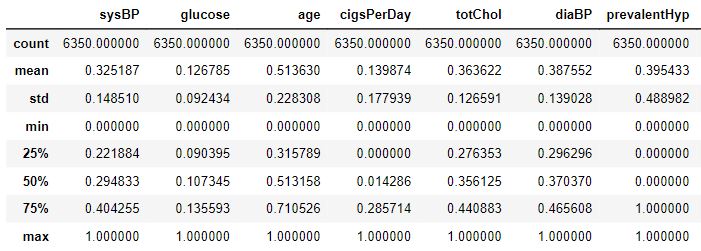
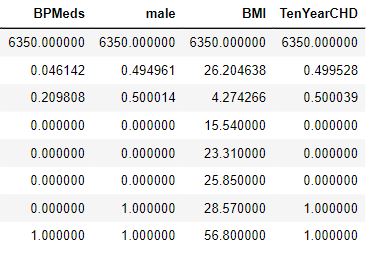
5) Feature Scaling
5) Train-Test split
#Train-test split X=df.drop(['TenYearCHD'],axis=1) y=df['TenYearCHD'] X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.4, random_state=0)
6) Hyperparameter Tuning
#Number of trees
n_estimators = [int(i) for i in np.linspace(start=100,stop=1000,num=10)]
#Number of features to consider at every split
max_features = ['auto','sqrt']
#Maximum number of levels in tree
max_depth = [int(i) for i in np.linspace(10, 100, num=10)]
max_depth.append(None)
#Minimum number of samples required to split a node
min_samples_split=[2,5,10]
#Minimum number of samples required at each leaf node
min_samples_leaf = [1,2,4]
#Create the random grid
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf}
gb=GradientBoostingClassifier(random_state=0)
#Random search of parameters, using 3 fold cross validation,
#search across 100 different combinations
gb_random = RandomizedSearchCV(estimator=gb, param_distributions=random_grid,
n_iter=100, scoring='f1',
cv=3, verbose=2, random_state=0, n_jobs=-1,
return_train_score=True)
7) Machine Learning classification models fitting
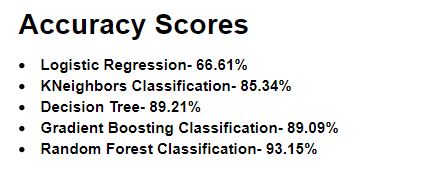
Traditional Machine Learning classification models such as Logistic Regression, KNeighbors Classifier, Decision Tree, Gradient Boosting Classifier, and Random Forest Classifier were fit for predicting the target variable 'TenYearCHD'.
#For Random Forest rfc=RandomForestClassifier(n_estimators=900,max_depth=50,random_state=0) rfc.fit(X_train,y_train) y_pred=rfc.predict(X_test)
Results:
Random Forest Classifier performed the best with an accuracy score of 93.15%.
Future Work:
Furthermore, the performance can be enhanced by using Ensemble and Hybrid Machine Learning techniques.
Project Files
| .. | ||
| This directory is empty. | ||
