Identifying hand digit in Python using TensorFlow and OpenCV
 ALBINUS B
Sep 28, 2020
ALBINUS B
Sep 28, 2020
The hand digit is captured, processed, and predicted using the model trained. Tensorflow and OpenCV are used majorly. project is done in python
This is my version of the python code predicting the hand digit shown. It allows the user to capture a picture of the sign shown and have the program take a guess of which digit it is from the trained model. This uses a convolution neural network model. Dataset of 12,713 images was used to train the model.
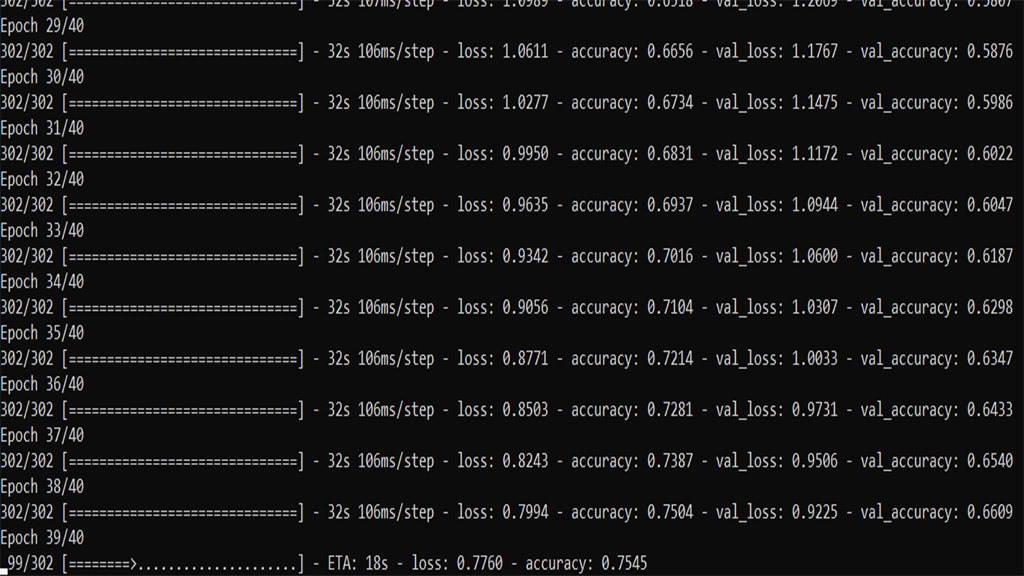
Stage 1: Training the model
A dataset of 12,713 images was downloaded and split into 9081 images for training and 3632 images for the test. The dataset was loaded using ‘Flow_from_directory’ in the ImageDataGenerator. A convolution neural network of sequential type with 7 layers was formed. and softmax activation is used In the last layer since the prediction involves {None, one, two, three, five}. the training images were of size 300 x 300.
#1st layer
Conv2D(16, (3, 3), input_shape=(300,300,1),activation='relu')
MaxPooling2D(pool_size=(2, 2))
#2nd layer
Conv2D(32, (3,3), activation='relu')
l4=MaxPooling2D(pool_size=(2, 2))
3rd layer
Conv2D(64, (3,3), activation='relu')
MaxPooling2D((2,2))
4th layer
lConv2D(64, (3,3), activation='relu')
MaxPooling2D((2,2))
#5th layer
Conv2D(64, (3,3), activation='relu')
MaxPooling2D((2,2))
#6th layer
Flatten()
Dense(512, activation='relu')
#last layer 7
Dense(6, activation='softmax')
The model was trained using the fit_generator function for 40 epochs. model is trained for accuracy of 80%. (and saved as OH-HO2.h5)
Stage 2: capturing the image and processing it.
First, webcam = cv2.VideoCapture(0) is initialized and the webcam.read() is called within a while loop to give an output video. Click ‘s’ to save or click ‘q’ to exit. For sake of simplicity, the image is saved when ‘s’ is pressed.
Second, the saved image is read. we apply Gaussian blur to the image. Note that kernel sizes must be positive and odd and the kernel must be square. Then we use an adaptive threshold using 11 nearest neighbor pixels.
---- Capturing the image ----
key = cv2. waitKey(1)
webcam = cv2.VideoCapture(0)
while True:
try:
check, frame = webcam.read()
cv2.imshow("Capturing", frame)
key = cv2.waitKey(1)
if key == ord('s'):
cv2.imwrite(filename='saved_img.PNG', img=frame)
webcam.release()
img_new = cv2.imread('saved_img.PNG', cv2.IMREAD_GRAYSCALE)
img_new = cv2.imshow("Captured Image", img_new)
cv2.waitKey(1650)
cv2.destroyAllWindows()
print("Processing image...")
break
elif key == ord('q'):
print("Turning off camera.")
webcam.release()
print("Camera off.")
print("Program ended.")
cv2.destroyAllWindows()
break
except(KeyboardInterrupt):
print("Turning off camera.")
webcam.release()
print("Camera off.")
print("Program ended.")
cv2.destroyAllWindows()
break

----- processing the image ----
img_ = cv2.imread('saved_img.PNG', cv2.IMREAD_GRAYSCALE)
dst = cv2.GaussianBlur(img_.copy(),(9,9),0)
process = cv2.adaptiveThreshold(dst, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)
process = cv2.bitwise_not(process, process)
kernel = np.array([[0., 1., 0.], [1., 1., 1.], [0., 1., 0.]], np.uint8)
process = cv2.dilate(process, kernel)

Stage 3: predicting the image
The model is loaded using load_model from tensorflow.keras.models. The processed image is resized to 300 x 300 and then passed to predict function. The prediction is printed.
img=cv2.resize(process, (300, 300),interpolation = cv2.INTER_AREA)
model = load_model('OH-HO2.h5')
pred = classes[np.argmax(model.predict(img.reshape(1, 300, 300, 1), batch_size=1))]
print(pred)

Delivarables:
- the project could be further extended to predicting hand gestures and signs
- it could be improved to predict it on the live video feed
Note: I couldn't upload the dataset since its very large.
Project Files
| .. | ||
| This directory is empty. | ||
