Implementing FP Growth Algorithm in Machine Learning using Python
 R. Gayathri
Dec 16, 2020
R. Gayathri
Dec 16, 2020
Implementing Frequent Pattern Growth Algorithm using Associative Rule learning to design book recommendation system in Python.
Several data items are connected together based on certain rules, which discovers the relations
between them in large databases. FP Growth is one of the associative rule learning techniques
which is used in machine learning for finding frequently occurring patterns.
It is a rule-based machine learning model. It is a better version of Apriori method. This is
represented in the form of a tree, maintaining the association between item sets. This is called
the frequent pattern tree.
From this frequent pattern tree, a conditional pattern base derived and conditional FP tree, from
which the frequently occurring pattern is identified. This is on the high level. Now, lets us get
into a detailed view on how this works.
ALGORITHM
Let T = {T1,T2,T3,T4,T5} set of transactions and I = {I1,I2,I3,I4,I5} set of items

There are list of items and various transactions. The first step is the find the support count of
each item. Support count is the frequency of items, that is how many times each item occurs
in the transactions. The database is scanned completely to find the support count value.

FP tree generation:
FP tree is created with the root node value as “null”
The transaction database is scanned again and all the items in each transaction is examined iteratively. For every transaction, the itemset is arranged in descending order according to the support value. The branches of the tree are constructed with the transaction items in descending order. This is repeated for every transaction.
If any itemset of the transaction is already present in another, with the same sequence of itemset, then this transaction branch would share a common prefix to the root, which means that the new item is linked to the common itemset from a different transaction.
The count of the item is incremented by one every time it occurs in a transaction, whether it is a new item or an existing item. The branches are created and linked accordingly. This results in a well-constructed FP tree with support count value for each item in the itemset
Conditional Database creation:
The next step is to create a conditional database with the constructed FP tree. Conditional pattern is a sub-database consisting of prefix paths in the FP tree occurring with the lowest node (suffix).
The lowest node Ni which has the lowest support value is traced back to the root, that is, the path is traversed along the links of the items.
The path is written along with the support value of Ni at the end, in the form of sequences. The minimum support value is 0.2, therefore, an FP tree is constructed with the items is the path which has support value>=0.22. This step is repeated iteratively for all the items.
Frequent patterns generation:
Frequent patterns are generated from the conditional FP tree.
This is done by forming links between node ni with each item in the conditional FP tree.
TERMS:
Support : S(i) = no: of transactions in which i appears / Total no: of transactions It is the proportion of transactions in the database that contain i
Confidence : C(i->j) = S(i U j) / S(i)
It is likelihood of itemset j being purchased with itemset i.
Lift : L(i->j) = S(i U j) / S(i) * S(j)
It is a ratio of observed support to expected support if i and j were independent.
Antecedent and Consequent : i -> j implies if i, then j P is the Antecedent and Q is the Consequent
IMPLEMENTATION:
Dataset:
In this example, we are using the transaction of books dataset consisting of 5 transactions and 5 items, where each transaction has m<5 items.
Code:
Importing all the needed libraries.
import pandas as pd from mlxtend.preprocessing import TransactionEncoder from mlxtend.frequent_patterns import association_rules from mlxtend.frequent_patterns import fpgrowth
Here we use pandas for data analysis, mlxtend which is an extended library useful for day- today functions. It has inbuilt methods for fp growth algorithm.
dataset = [['TFIOS', '5 feet apart', 'Walk to remember'], ['TFIOS', 'Walk to remember'], ['Divergent', 'Harry Potter','Walk to remember'], ['TFIOS', 'Five feet apart'], ['Divergent','Harry Potter']] te = TransactionEncoder() te_array = te.fit(dataset).transform(dataset) df = pd.DataFrame(te_array, columns=te.columns_)
The dataset is loaded into a variable. This includes a transaction table containing itemset. A data frame is created on the table
This is the visualization of the data
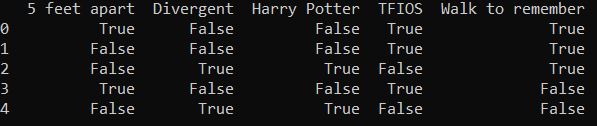
The row represents the items
The column represents the transactions
The “True” represents that the item is present in that transaction. The “False” represents that the item is not present in that transaction.
frequent_itemsets_fp=fpgrowth(df, min_support=0.02, use_colnames=True)
This function finds the frequently bought items with support value>-0.02
rules_fp = association_rules(frequent_itemsets_fp, metric="confidence", min_th reshold=0.8)
This finds the association rules for the particular dataset.
Finally, print the frequent itemset along with their support value , association rules along with their antecedent, consequent, support and lift values.


CONCLUSION:
Frequent Pattern Growth Algorithm is one of the best machine learning models for association rule-based learning. It has an advantage over Apriori algorithm, because unlike Apriori which generates all the candidate item sets, FP Growth generates item sets which are frequently occurring only. Therefore, it can be used to discover relations between various dataset effectively.
Project Files
| .. | ||
| This directory is empty. | ||
