Implementing Gaussian Mixture Model in Machine Learning using Python
 R. Gayathri
Dec 06, 2020
R. Gayathri
Dec 06, 2020
Implementing Gaussian Mixture Model using Expectation Maximization (EM) Algorithm in Python on IRIS dataset.
Several data points grouped together into various clusters based on their similarity is called clustering. Gaussian Mixture Model is a clustering model that is used in unsupervised machine learning to classify and identify both univariate and multivariate classes.
Gaussian Mixture Model is a probability-based distribution model. It assumes that all classes are distributed in a gaussian distribution, which is the same as normal distribution but is two-dimensional. Normal distribution is a well-known concept where the data points are symmetrically distributed close to the mean value and it is visually represented in the form of a bell curve, which is the probability density function.
This pattern is the basis for comprehending the working of this model. GMM uses the Expectation-Maximization (EM) Algorithm which is used to find the optimal value for mean, covariance matrix and mixing coefficients.
ALGORITHM
In single dimensions, the normal distribution has two parameters, µ (mu) and σ (sigma). µ is the mean, which is the centre of the distribution and the σ is standard deviation, which is range of the distribution. Higher the value of sigma, the more it would be spread out. In higher dimensions, there are three parameters, µ (mu), ∑ (sigma) and ᴨ (pi). µ is the mean, the σ is the covariance matrix which has the size equal to the number of dimension and ᴨ is probability. The high-level view of this algorithm is to find the optimal values for these parameters.
So, the question is, how do we pick the best values for the parameters?
For instance, IRIS dataset has categories of flowers. The attributes are the length and width of each /category of sepals.
 where k is number of clusters
where k is number of clusters
wk is length of k,
lk is width of k
Let us assume that there are random observations . What is the probability of seeing these observations in either of the clusters? From the above, we can see that there are 3 options. The points in can belong to distribution generated by either of the classes. The ultimate aim is to maximise the probability of seeing the observation for some given µ, ∑, and ᴨ.
Mathematical Formula:

The above formula is to calculate the occurrence of the observations in the clusters.
![]() is the probability of X for given
is the probability of X for given ![]()
![]() is the normal distribution of k
is the normal distribution of k
![]() is the probability of k
is the probability of k
where k is the number of clusters.
Defining auxiliary quantities:
This is done to maximise the probability with respect to ![]()
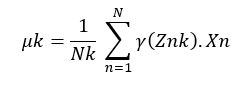
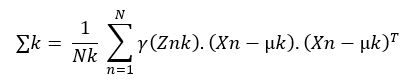
![]()
Znk is 0(if Xn not in class k) and 1(if Xn in class k)
![]() (By Bayes Theorem)
(By Bayes Theorem)
![]()
The inference from these formulae is that, depends on and vice versa.
Therefore the Expectation Maximisation(EM) Algorithm has the following steps:
- The values
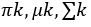 of are initialized.
of are initialized.
- The
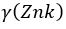 is computed
is computed
- are computed according to the derived
Repeat from step 2 iteratively until we converge at a log-likelihood value, in other words until he probability of occurrence is maximised.
IMPLEMENTATION
Dataset:
In this example, we are using the IRIS dataset from scikit-learn which consists of 3 classes and 50 samples per class. Therefore a total of 150 samples are present.
Code:
Importing all the needed libraries. import numpy as np import pandas as pd import matplotlib.pyplot as plt from pandas import DataFrame from sklearn import datasets from sklearn.mixture import GaussianMixture
Here we use numpy for working on large and multidimensional arrays, pandas for data analysis, matplotlib for plotting the graphs, sklearn to import dataset and GMM functionalities
iris = datasets.load_iris() X = iris.data[:, :2] d = pd.DataFrame(X) plt.scatter(d[0], d[1])
The dataset is loaded into a variable. Only the first two attributes are taken into consideration: The length and width of the sepal. A data frame is created for the data and the points are plotted as a graph.
This is the visualization of the data points

gmm = GaussianMixture(n_components = 3) gmm.fit(d) labels = gmm.predict(d) d['labels']= labels d0 = d[d['labels']== 0] d1 = d[d['labels']== 1] d2 = d[d['labels']== 2] plt.scatter(d0[0], d0[1], c ='r') plt.scatter(d1[0], d1[1], c ='yellow') plt.scatter(d2[0], d2[1], c ='g')
Fit the GMM model for the dataset which expresses the dataset as a mixture of 3 Gaussian Distribution. This uses the Expectation Maximisation Algorithm. Each cluster is assigned a label and a colour for clear visualisation.
This is the visualisation of the clusters

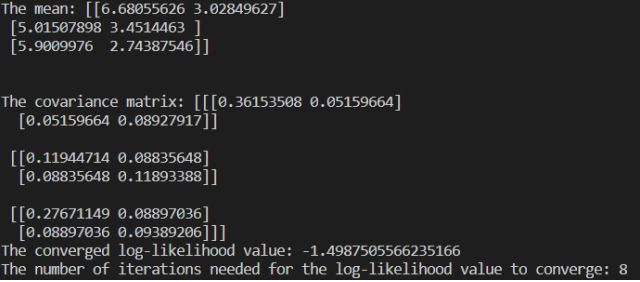
Finally, print the mean, sigma and converged log-likelihood values. The number of iterations to arrive at the result is also displayed.
CONCLUSION
Gaussian Mixture Model is one of the best machine learning models for multivariate classes. This model has an advantage over K-Means clustering when the clusters are of different sizes because one of the implicit assumptions of K-Means is that the clusters are about the same size. On the other hands, GMM searches for gaussian distribution and thus does a better job in locating clusters of different sizes as well, and therefore can be used to process and train large, multidimensional arrays and classify them effectively.
Project Files
| .. | ||
| This directory is empty. | ||
