Python based content extraction from PDFs
 Shalini Sinha
Aug 17, 2023
Shalini Sinha
Aug 17, 2023
Here we demonstrate how we can use PyPDF2 module to find specific content by defining patterns that match the desired text pattern.
To demonstrate the functionality of code we take medical report dataset to showcase the desired output:
We need to keep in mind that the quality and complexity of the PDF documents can have an impact on how accurately the text is extracted.
1. Adding the file's path and setting up PyPDF2 module:
PPDF2 libraryoffer extraction of text, pattern matching and text manipulation. PDFs have complex formatting or images.
2. Source code for extracting content:

3. Running the command for the output:
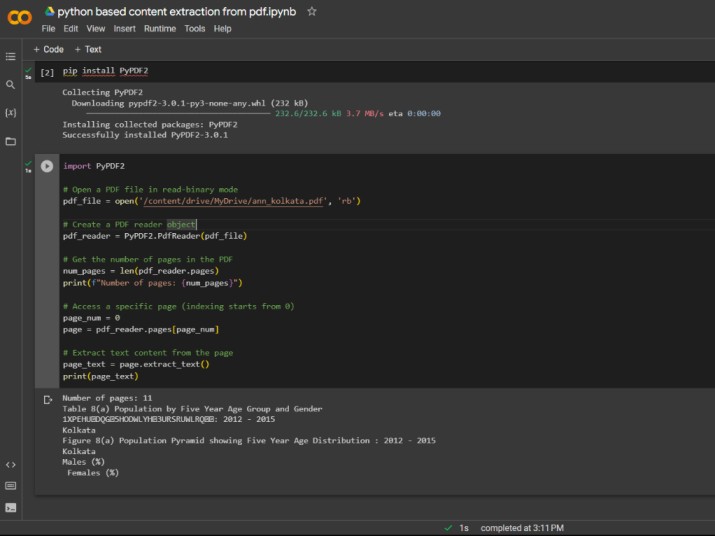
Outputs derived facilitating the information placed in the source code:
1. we get the desired information from the first page by indexing the correct page number.
2. Then extracted the desired text using the above code.
Project Files
/
Loading...
| .. | ||
| This directory is empty. | ||
